
Synthetic data: a solution to data scarcity and privacy
One of the most exciting Generative AI (GenAI) use cases for financial services and telcos is the generation of synthetic data. This data augmentation technology can help businesses improve the predictive accuracy of the models they use to assess credit risk and detect fraud.
Although synthetic data has existed in various forms for some time, the latest advancements in GenAI, specifically Conditional Tabular Generative Adversarial Networks (CTGANs), mean that synthetic data is now a viable option to enhance unbalanced training datasets and precisely simulate hypothetical scenarios.
Generating synthetic datasets has another significant benefit – it allows businesses to share data freely between different parts of their organisation and across borders. This sidestep of regulatory and compliance hurdles is possible because synthetic data is fully anonymised and thus contains no sensitive PII data.
Experian’s recent AI research shows that a lack of data is many businesses’ biggest data-related challenge. Synthetic data generation is an effective way to overcome this problem. This Q&A article answers all your data augmentation questions and provides some real-world examples of how synthetic data is helping businesses improve profitability.
What is data quality?
Data quality essentially means how well a dataset fits its intended use. Good quality data is sufficiently accurate and complete to provide a valid description of what it represents. This means it must be reliable and relevant for its purpose.
What is data augmentation?
Data augmentation involves the creation of synthetic data that accurately represents the statistical distribution of the original real-world data. This new data is then used to improve the predictive accuracy of any model, whether traditional or ML models. The new data enriches the dataset by providing a more balanced and diverse set of records that creates a better dataset resolution and helps prevent overfitting the model.
What is synthetic data?
Synthetic data is artificial data, generated via algorithms that produce new data that retains a statistically accurate representation of the original data. This means that synthetic data can be used to supplement imbalanced or insufficient datasets to improve the predictive accuracy of a model.
What is the best way to create synthetic data?
Various methods are used to create synthetic data. The most effective deep learning technique is a Conditional Tabular Generative Adversarial Network (CTGAN). This method delivers the most complex distribution of data and can include multiple data types in each model. Simple versions, such as Gaussian Copula or Variational Auto Encoders, may also be an alternative.
What are the benefits of using synthetic data?
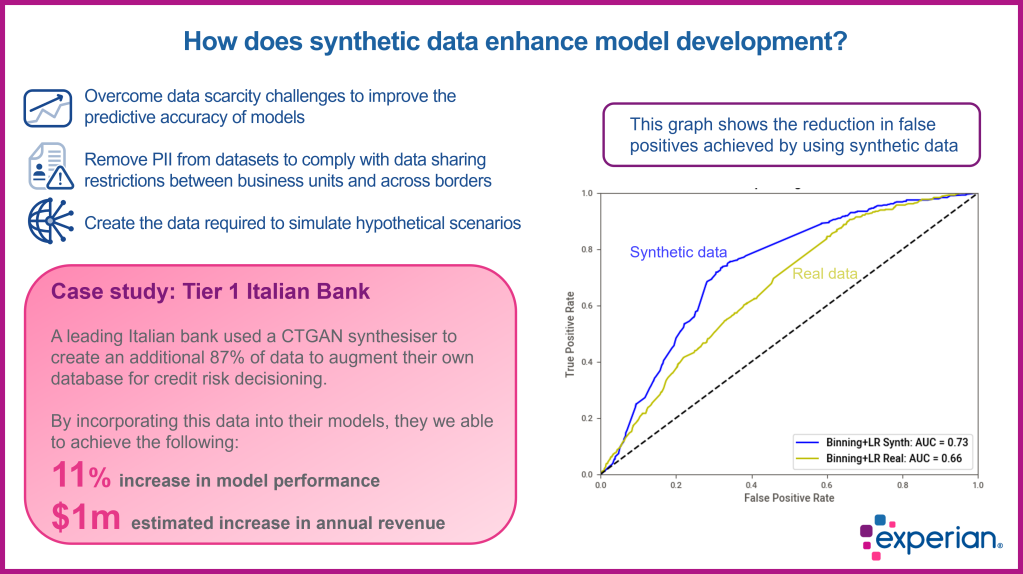
The main benefit of synthetic data is that it allows businesses to overcome data scarcity issues by creating additional data to improve the accuracy of their credit risk and fraud models. Another major benefit is that it allows businesses to create the data they need to simulate hypothetical future scenarios.
It can also reduce the complexity involved in sharing sensitive data. Furthermore, synthetic data helps simplify GDPR compliance since there is no need to retain the original data once the synthetic data is created.
How can synthetic data improve the predictive accuracy of models?
Data scarcity is often a challenge when developing new models. Synthetic data can help businesses overcome this difficulty by creating more diverse datasets with the ideal balance of data points or creating new ones that help generalise the models and reduce their potential biases. For example, by creating additional fraud data when the real-world training data lacks sufficient data points to develop a robust model. This additional data creates a more balanced training dataset that results in greater predictive accuracy.
How can synthetic data be used to simulate hypothetical scenarios?
Synthetic data can be used to model hypothetical economic situations, such as periods of elevated inflation or a recession. Understanding how a portfolio will react under these extreme conditions can help businesses identify any potential risks and take steps to mitigate them in advance.
Another area where synthetic data can be highly valuable is when entering new markets. In this situation, businesses may lack sufficient historically relevant data to develop accurate credit risk models. Synthetic data can be used to emulate potential credit behaviour in a new market to improve the predictive accuracy of credit decisions.
How can synthetic data help overcome compliance issues around data sharing?
Synthetic data is truly anonymised, which means that any sensitive PII data cannot be inferred from it. As a result, it can be freely shared between business units and across borders as it complies with current privacy regulations around the world. As data-sharing regulations tighten, synthetic data offers a simple and effective way to safely share data without risk.
How does a CTGAN model create synthetic data?
In the case of CTGANs, it uses two neural networks that iteratively learn from each other to produce synthetic data that is indistinguishable from the training dataset. To achieve this, one of the neural networks (the generator) produces new data, while the other neural network (the discriminator) classifies the data as either real or fake.
The generator then uses this feedback to improve the next round of outputs. Over time the quality of the synthetic data improves until the discriminator is unable to determine if it is from the original dataset or is newly created.
How can synthetic data address bias?
Creating synthetic data allows you to selectively correct imbalances that represent bias in your data. In other words, you can generate data for a specific demographic or population that is underrepresented. This means you can create a training dataset that more accurately represents a population and directly address one of the main causes of bias.
What is the secret to creating high-quality synthetic data?
For synthetic data to statistically reflect real-world data as closely as possible, it needs a suitably representative training dataset. The quality of synthetic data is heavily dependent on the quality of this original real-world dataset. Equally important is selecting the right type of data generation model, for example CTGANs. Experian’s extensive global datasets provide an ideal training dataset for a wide variety of best-in-class synthetic data.
Are you interested in using synthetic data in your models?
Experian is uniquely positioned to help your business produce synthetic data via our comprehensive bureau datasets. Once the data imbalance within your model is identified, we can produce the data needed to correct this imbalance. The results of adding synthetic data to a model can be considerable, in some cases as much as a 20-point improvement in the Gini coefficient.
If you would like to know more about how synthetic data can help improve your analytical process, then please contact me via the form below.