
Why is explainability so important? Well, it is the key to unlocking the potential of Machine Learning for credit decisions.
Delivering an improved model is only part of the equation. The other part is the ability to explain the logic behind the calculation. Without it, there are regulatory implications as credit risk models are classified as high-risk type models.
In fact, regulation dictates that every decision within credit risk should be fully explainable. This means that many businesses have avoided the use of Machine Learning for fear of not being able to explain the reason behind the decisions made by an ML-based model.
The models must be easily interpretable by the humans evaluating the output and must be delivered in a clear and transparent manner with a reason code.
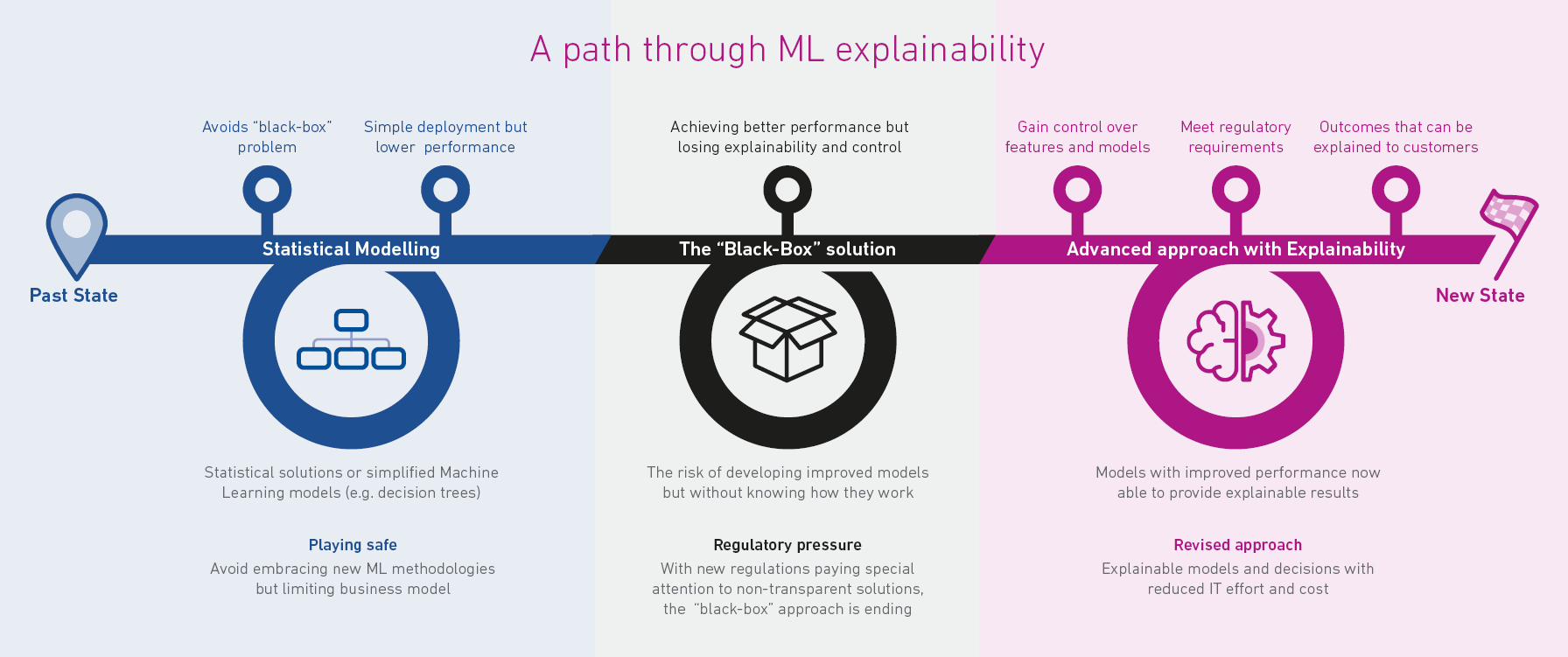
Breaking out of the black box
One of the major concerns limiting implementation is the so-called ‘black box’ of Machine Learning, related to some methods developed using this process.
As analytical capability has developed from statistical models to Machine Learning based models, it has created more sophisticated algorithms that have ended up becoming hard to explain.
As covered in my previous blog, these algorithms can deliver a significant improvement in model performance, but many have not been able to provide the required transparency in terms of how the decision came to be made.
In the context of credit risk, this means that an ML model may be able to deliver improvements in the ability to identify defaults for new customer applications but without the ability to explain how the result was generated.
This opens many potential concerns around trust in the model and fairness or ethics of the decisions.
Lenders need to be able to explain decisions to consumers for transparency and for regulatory purposes.
Specific departments within an organisation (fraud, risk, internal audit) need to understand what impacted the score, how it relates to referrals, and its influence on approve or decline decisions.
Any ML model developed for credit decisioning must have a transparent methodology built in.
The good news is that ML explainability is not only a possibility but a reality that is already being deployed successfully in credit decisioning.
Businesses can now access ML solutions that deliver an advanced approach but with full explainability and transparency, allowing them to break out of the black box.
Building trust in the process
Explainability is important because it builds trust in the process.
Within each organisation, teams will rely on explainability to either fulfil specific tasks or to understand and discover improvements in the model performance.
Regulators and auditors require businesses to ensure that they can provide evidence of the rationale behind lending and credit decisions.
Consumers also have the right to receive information about what contributed most to a given score or decision. Reason code logic allows businesses to be able to explain why a score was given.
Advanced ML models developed and deployed with full explainability means businesses can now optimise performance.
Comprehensive documentation is available to meet the regulatory requirements, giving businesses the confidence to deploy these models and take advantage of the performance potential.
Upgrading your models
ML can provide the same transparency for credit risk modelling as traditional models, but it is important to understand that not all ML models provide the same level of transparency.
Upgrading from traditional logistic regression models to Machine Learning models increases predictability, but the ML methodology must provide explainability to ensure the performance uplift comes with the confidence of transparency for auditing and regulatory purposes.
Gradient boosting machines (GBMs), for example, is a type of ML algorithm that is highly predictive and offers greater transparency than some other popular Machine Learning frameworks such as neural network models.
GBMs are built from a combination of decision tree sub-models, which means you can understand how these are constructed to trace the inputs into the decision.

SHAP (SHapley Additive exPlanations) Values
One such approach to improving the interpretability of ML models is the use of SHAP-values.
This involves the ability to provide contrastive explanations to understand which model features contributed most and least to the result and, it is model agnostic. It can be applied to several types of ML models, ensuring that businesses can have ML explainability in several ways. It is best explained using the concept of a game and players.
By using SHAP-values we can understand the relative contribution of each player to the outcome of the game.
In the same way, we can understand what features of a Machine Learning model led to the outcome.
For example, Experian has developed an approach based on SHAP for Machine Learning projects and has integrated it into its core business to help businesses with explainable credit risk, affordability, and fraud decisions.
This allows businesses to understand, for example, the reasons behind a credit decision, which can be simplified further into reason codes.
Businesses will then have evidence of how the decision was made for auditing and regulatory purposes and for internal teams to assess model performance for potential improvements.